CS 공부 내용 정리
CSAPP, OSTEP 보면서 궁금한 내용 정리
CSAPP, OSTEP를 읽으면서 이론적 지식을 공부하는 것도 좋지만, 실제 세계에서 어떤 식으로 동작하는가... 도 많이 궁금해하는 편이라 같이 메모하려고 함.
CSAPP
1.2 - 목적파일은 어떻게 연결되는가? 링커는 어떻게 동작하는가?
근데 이거 7장에 나오는 듯? 너무 딥하게 팔 필요는 없고 이런 이미지 정도로만 생각하고 있어도 충분해보임.
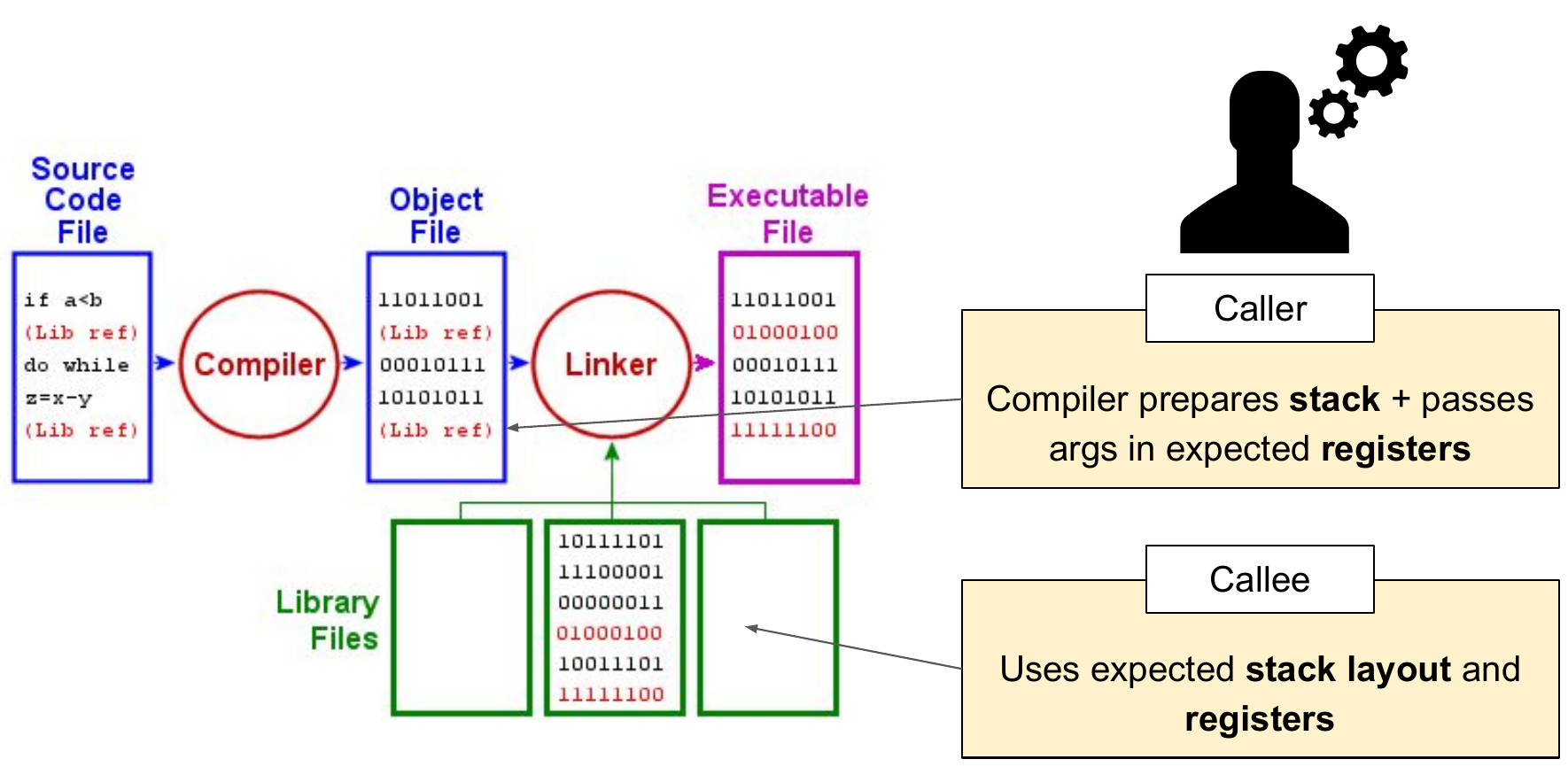
관련 자료
- [CSAPP 7장 완전 정복] 7.12 공유 라이브러리의 핵심 기술 - PIC, GOT, PLT
- Position Independent Code (PIC) in shared libraries - Eli Bendersky's website
- Library order in static linking - Eli Bendersky's website
1.4 - 컴퓨터/CPU는 실제로 어떻게 생겼는가?
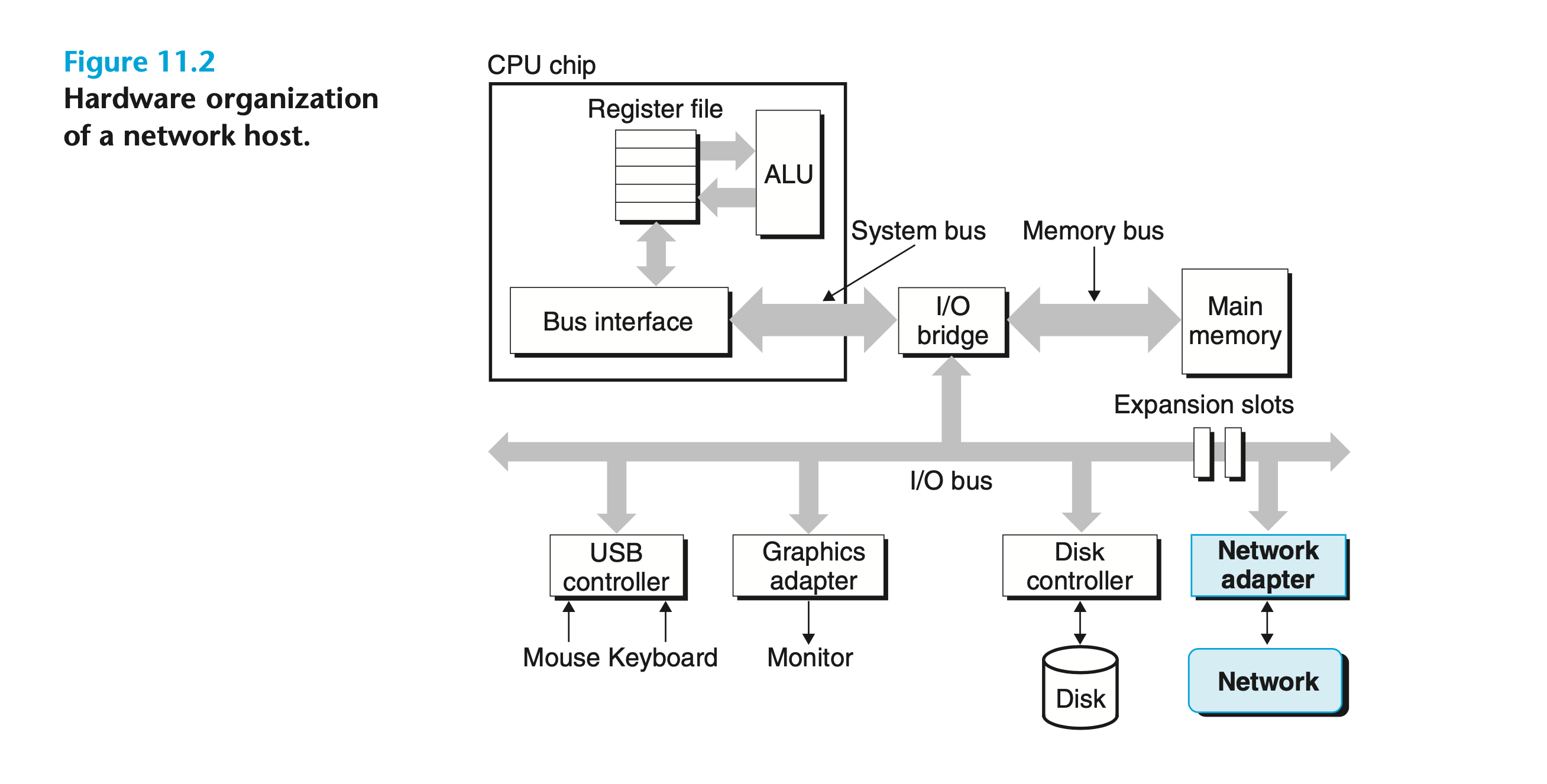
이런 구조는 많이 보는데, 그래서 실제로 어떻게 생겼나?
컴퓨터
I/O Bridge가 나온 모델은 상대적으로 현대적인 모델이라 볼 수는 없었고, 단순한 Ben Eater를 보면 도움이 된다.
실제 구현해보려면 하드웨어를 만지는 것보다는 코드로 구현하는 Nand2Tetris를 하는게 좋을 듯 하다.

Word 크기가 CPU의 처리 단위에 의해 결정된다는 점이 실물에서도 그대로 드러난다. 8-bit CPU이므로 한 번에 8-bit만 처리할 수 있고, 메모리 주소 공간도 그에 맞게 제한된다.
명령어 역시 8-bit로 구성되어 있다. "ben eater 8 bit computer instruction set"으로 검색하면 확인할 수 있다.
한 클럭에 하나의 신호만 전송하므로, 위 이미지의 버스 배선도 실제로 8개의 선으로 이루어져 있다. 이 원리 자체는 현대 프로세서에서도 동일하다(버스 폭이 넓어졌을 뿐이다).
관련 자료
- Ben Eater의 8-bit 컴퓨터 영상.
- 다른 사람이 구현한 Ben Eater 컴퓨터의 simulation도 있다. 영상, LOGISIM 시뮬레이터 파일 소개
- Nand2Tetris 개인적으로 정리한 자료
- Nand2Tetris ALU 회로 예시
 출처
출처
컴퓨터는 아주 간단하게 보면 정해진대로 전기 회로를 보내면, 클럭마다 메모리(레지스터,RAM)에 값을 쓰는걸 반복할 뿐인 기계이다.
CPU
실제 8bit의 CPU는 이렇게 생겼다. 버스도 8개 사용하는거 볼 수 있음.


visual6502.org에서 JS로 시뮬레이션도 가능하다.
버스, I/O Bridge
CPU의 내부 데이터 경로는 기본적으로 워드 크기(32-bit, 64-bit 등)에 맞춰져 있지만, 외부 I/O 버스(PCIe, USB, SPI 등)는 독자적인 데이터 폭과 프로토콜을 가진다.
I/O Bridge(버스 컨트롤러)가 이 차이를 변환한다. 복잡한 버스 컨트롤러는 펌웨어가 있는 경우도 있음.
컴퓨터는 왜 2진수인가? 하드웨어와 관련해서
최근 CSAPP를 읽다가 하드웨어 관련 내용을 보면서 예전에 봤던 영상이 떠올랐다.
CD가 어떤 방식으로 동작하는지 간단하게 설명하는 영상이다. CD 표면에는 pit(홈)과 land(평면) 구조가 있는데, 레이저가 이를 지나가면 반사되는 빛의 세기가 달라진다. 이 차이를 센서가 감지해 전기 신호로 변환한다.
CD가 대부분 일회용인 이유도 여기에 있다. 기록할 때 물리적으로 구조를 바꿔버리기 때문이다. HDD도 비슷하게 물리적 상태를 이용하지만 방식은 다르다. 디스크 표면에 자기장을 부여해 그 방향으로 0과 1을 구분하고, 이를 다시 바꿀 수 있기 때문에 여러 번 읽고 쓰기가 가능하다.
이 이야기는 결국 왜 컴퓨터가 2진수를 사용하는가를 설명하는 현실적인 비유로도 볼 수 있다. 컴퓨터가 다루는 수학은 이진수지만, 실제 물리 세계의 신호는 연속적인 값이다.
문제는 현실 세계의 하드웨어(전압, 물리적 디스크 등)에는 항상 노이즈(noise)가 존재한다는 점이다. 그래서 이를 안정적으로 처리하기 위해 여유 구간(noise margin)을 두고 신호를 구분한다. 이때 상태 수가 많아질수록 구분이 어려워지기 때문에, 두 상태로 나누는 방식이 가장 안정적이고 단순한 설계가 된다.
즉 다른 방식이 물리적으로 불가능한 것은 아니지만, 공학적으로 효율이 떨어지기 때문에 대부분의 컴퓨터가 2진 시스템을 사용한다고 볼 수 있다.
1.7 - 운영체제는 하드웨어를 관리한다.
추상화 레이어
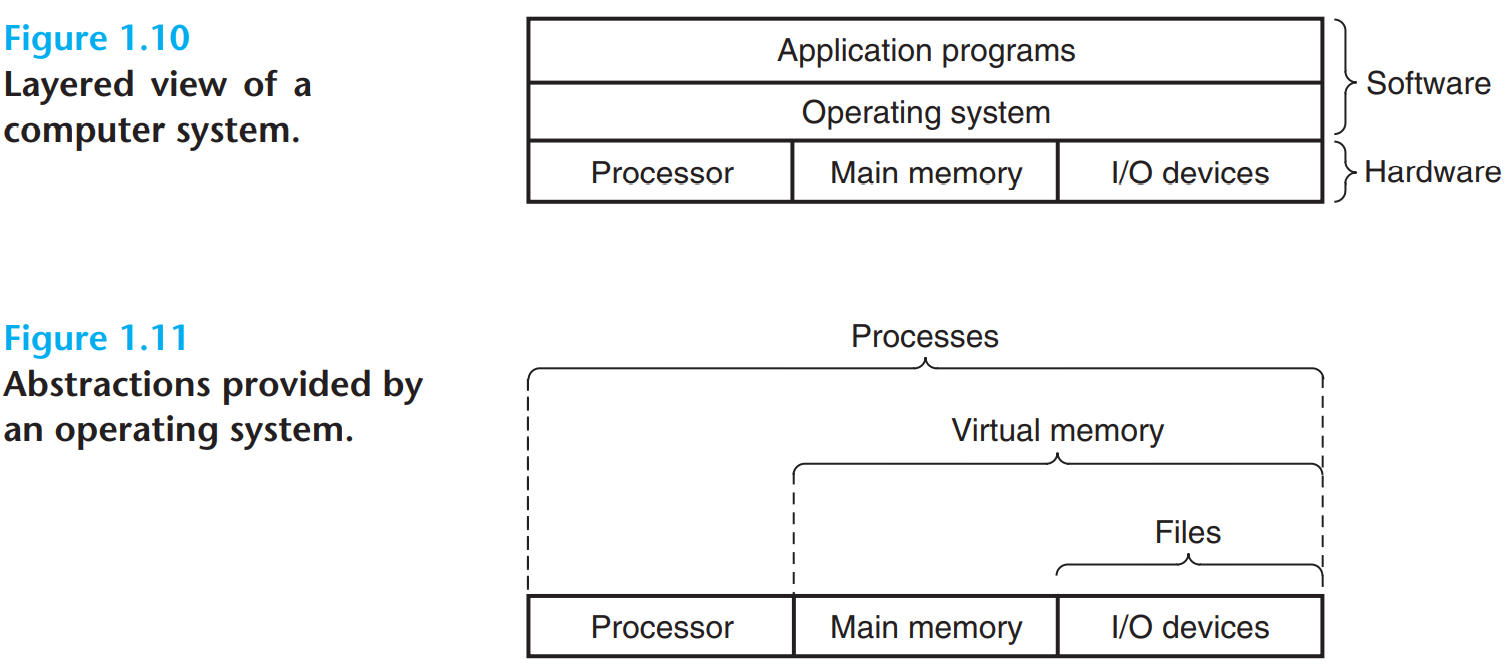
기존에는 그림 1.10처럼 단순한 구조로만 이해하고 있었는데, 그림 1.11의 관점이 더 인상적이었다.
운영체제는
- I/O 장치를 파일(file)로,
- 가상 메모리를 파일(I/O 장치) + 물리 메모리로,
- 프로세스(process)는 프로세서와 가상 메모리(메모리 + I/O)로 추상화한다.
이걸 단순한 계층 구조로도 볼 수 있지만, 추상화 레이어로 해석할 수도 있다.
가상 메모리는 파일과 메모리를 합쳐서 메모리가 무한한 것처럼 추상화하고, 프로세스는 프로세서와 가상 메모리를 사용하여 무한한 독립된 공간인 것처럼 추상화된다.
이런 적으로 생각해본 적 없었는데 이게 인상 깊었다.
장치 파일
커널이 하드웨어와 유저레벨 중간에서 추상화를 제공해준다는 것의 좋은 예시.
라즈베리파이는 GPIO, I2C, SPI 같은 하드웨어에 /sys, /dev 같은 값을 쓰면,
바로 LED가 켜지고 꺼지는 등의 반응을 볼 수 있다.
보안 관점
운영체제는 유저 레벨과 커널 레벨을 분리하여 역할을 나눈다. 이는 시스템 안정성과 보안을 확보하기 위한 구조이다.
이러한 구조의 중요성을 보여주는 사례로 2024년 CrowdStrike 장애가 있다.
해당 사건은 커널 모드에서 동작하는 보안 드라이버가 자동 업데이트 과정에서 오류를 포함하게 되면서 발생하였다. 그 결과 해당 소프트웨어를 사용하는 다수의 Windows 시스템이 동시에 다운되며 전산망이 마비되었다.
이 사례는 커널 레벨 코드에 문제가 발생할 경우 시스템 전체에 치명적인 영향을 줄 수 있음을 보여주며, 따라서 일반 프로그램이 커널에 직접 접근하지 못하도록 분리하는 것이 왜 중요한지 설명해준다.
OSTEP
POSIX, glibc 알아보기
- UNIX는 Bell Labs에서 시작됨
- 이후 여러 회사/기관이 각자 UNIX 변형을 만듦 → 호환성 문제 발생
- 이를 해결하려고 IEEE가 POSIX라는 표준을 정의
- Linux는 UNIX가 아니라 Unix-like OS이며 POSIX를 따르는 방향으로 설계됨
- Linux는 POSIX를 완전히 준수하지 않지만, glibc 등을 통해 POSIX 호환 환경을 제공한다.
- POSIX는 API, 동작 방식, 규칙을 명세한다. (정확한 명세를 위한 용어 정의도 있다.)
-
glibc(글립씨, GNU C Library)는 C 표준 라이브러리이면서 POSIX API를 구현하고 GNU 확장 기능까지 포함한다.
-
거의 대부분의 GNU/Linux 배포판에서 glibc를 사용한다.
-
macOS는 Unix 계열(OS X/Darwin 기반)이며 POSIX를 상당 부분 준수하지만 완전한 호환은 아니다. 따라서 glibc를 사용하지 않고, 자체 libc(libSystem)를 사용한다.
-
그래서 glibc는 유저레벨의 구현이고, pthread_create 같은 함수는 시스템 콜이 아니다.
-
pthread_create는 내부적으로 clone() 시스템 콜을 사용하여 스레드를 생성하고, 필요 시 mmap() 등을 이용해 스택 메모리를 할당한다.
원자연산, 스핀락, 뮤텍스, 세마포 알아보기
AI로 정리된 내용임. 시간 관계상 다듬지는 못했는데, 나중에 시간나면 다듬기.
atomic instruction
atomic instruction: 하드웨어가 제공하는 원자적 연산. 실행 도중 다른 코어가 끼어들 수 없음을 하드웨어 레벨에서 보장한다.
대표적인 것들:
- test-and-set (TAS): 메모리 값을 1로 세팅하면서 이전 값을 리턴. x86의
xchg가 이에 해당. - compare-and-swap (CAS): 메모리 값이 expected와 같을 때만 new로 교체. x86의
lock cmpxchg. - load-linked / store-conditional (LL/SC): ARM, RISC-V 계열. 두 명령어 쌍으로 atomicity를 보장.
- fetch-and-add (FAA): 값을 atomic하게 증가. x86의
lock xadd.
전부 결국 이 하드웨어 atomic instruction 위에 쌓여 있다. OSTEP이 여러 가지를 나열하는 이유는 각각의 표현력(expressive power)과 성능 특성이 다르기 때문이다.
예를 들어 TAS로 스핀락은 쉽게 만들지만, lock-free 큐 같은 건 CAS 없이는 사실상 못 만든다. CAS가 TAS보다 표현력이 강하다. 그리고 LL/SC는 ABA 문제에서 CAS보다 유리하다.
OSTEP이 이걸 다 보여주는 건 "종류가 많아서"가 아니라, 각각이 풀 수 있는 문제의 범위가 다르기 때문이다.
Lock-based vs Lock-free에서의 차이:
- Lock-based: TAS든 CAS든 뭘 쓰든 상관없다. 어차피 lock 잡고 → critical section → unlock 패턴이니까, TAS 하나로 충분하다.
- Lock-free: CAS가 사실상 필수다. 이유는 lock-free의 핵심 패턴이 "현재 상태를 읽고, 새 상태를 계산하고, 바뀌지 않았을 때만 반영"이기 때문이다. 이 조건부 쓰기가 CAS다. TAS는 조건 없이 무조건 덮어쓰니까 이 패턴을 표현할 수 없다.
전형적인 lock-free 패턴:
do {
old = load(ptr);
new = compute(old);
} while (!CAS(ptr, old, new)); // 실패하면 재시도TAS로는 이 "old가 아직 유효한지 확인"하는 부분을 표현할 방법이 없다.
이론적 근거는 Herlihy (1991)의 consensus number 개념이다. TAS의 consensus number는 2로, 2개 스레드까지만 wait-free consensus를 풀 수 있다. CAS는 consensus number가 ∞여서 임의의 N개 스레드에 대해 lock-free/wait-free 자료구조를 구현할 수 있다. 이게 CAS가 근본적으로 더 강력한 연산인 이유다.
참고: Herlihy, M. (1991). "Wait-free synchronization." ACM Transactions on Programming Languages and Systems, 13(1), 124–149.
스핀락, 뮤텍스, 세마포
계층 구조:
하드웨어 atomic instructions (TAS, CAS, LL/SC, FAA)
↓ 이걸로 구현
스핀락
↓ 이걸로 구현 (+ OS sleep/wakeup 메커니즘)
뮤텍스 / 세마포어
↓ 이걸로 구현
고수준 동기화 (condition variable, barrier, rwlock 등)1. 스핀락 (Spinlock)
가장 기본적인 lock. atomic instruction 하나로 구현 가능하다. lock을 못 잡으면 busy-wait(무한루프)하면서 계속 시도한다.
TAS 기반 스핀락 (가장 단순한 형태):
typedef struct {
int flag; // 0 = 사용 가능, 1 = 잠김
} spinlock_t;
void spin_lock(spinlock_t *lock) {
while (test_and_set(&lock->flag) == 1)
; // 이전 값이 1이면 누가 잡고 있는 것 → 재시도
}
void spin_unlock(spinlock_t *lock) {
lock->flag = 0; // store만 하면 됨 (atomic store)
}test_and_set(&flag)은 flag를 1로 세팅하고 이전 값을 리턴한다. 이전 값이 0이었으면 내가 lock을 잡은 것이고, 1이었으면 누군가 이미 잡고 있는 것이다.
x86 실제 구현 (GCC inline asm):
void spin_lock(spinlock_t *lock) {
while (__sync_lock_test_and_set(&lock->flag, 1))
; // GCC built-in: xchg 명령어로 컴파일됨
}
void spin_unlock(spinlock_t *lock) {
__sync_lock_release(&lock->flag); // flag = 0 + memory barrier
}CAS 기반 스핀락:
void spin_lock(spinlock_t *lock) {
while (!__sync_bool_compare_and_swap(&lock->flag, 0, 1))
; // flag가 0일 때만 1로 바꾸기 시도
}
void spin_unlock(spinlock_t *lock) {
__sync_lock_release(&lock->flag);
}CAS로도 스핀락을 만들 수 있지만, TAS로 충분하다. CAS를 쓴다고 스핀락이 더 좋아지지 않는다.
스핀락의 문제점:
- CPU 낭비: lock을 못 잡으면 while 루프를 돌면서 CPU 사이클을 소모한다.
- 단일 코어에서 최악: lock을 잡은 스레드가 스케줄링되어야 unlock할 수 있는데, 대기 스레드가 CPU를 점유하고 있으면 그게 안 된다.
- 공정성 없음: 어떤 스레드가 먼저 lock을 잡을지 보장이 없다. starvation 가능.
그럼 언제 쓰나?
- critical section이 매우 짧을 때 (수십~수백 나노초)
- 멀티코어 환경에서 context switch 비용보다 spinning이 싼 경우
- 인터럽트 핸들러 등 sleep할 수 없는 컨텍스트 (커널 내부)
Linux 커널은 스핀락을 광범위하게 사용한다.
spin_lock()/spin_unlock()함수가 그것.
참고: Love, R. Linux Kernel Development, 3rd ed. Chapter 10.
개선: ticket lock
기본 스핀락의 공정성 문제를 해결한 변형. 은행 번호표 시스템과 동일하다.
typedef struct {
int next_ticket; // 다음 번호표
int now_serving; // 현재 서비스 중인 번호
} ticket_lock_t;
void ticket_lock(ticket_lock_t *lock) {
int my_ticket = fetch_and_add(&lock->next_ticket, 1); // 번호표 뽑기
while (lock->now_serving != my_ticket)
; // 내 차례 올 때까지 대기
}
void ticket_unlock(ticket_lock_t *lock) {
lock->now_serving++; // 다음 번호 호출
}FIFO 순서가 보장되므로 starvation이 없다.
2. 뮤텍스 (Mutex)
스핀락 + OS의 sleep/wakeup 메커니즘. lock을 못 잡으면 busy-wait 대신 스레드를 재운다 (sleep queue에 넣는다). lock이 풀리면 OS가 대기 스레드를 깨운다.
핵심: 뮤텍스 내부에서도 sleep queue를 조작하는 부분은 임계 영역이다. 이 부분은 짧은 스핀락으로 보호한다. 즉, 뮤텍스 내부에 스핀락이 있다.
개념적 구현:
typedef struct {
int flag; // 0 = 사용 가능, 1 = 잠김
int guard; // 내부 스핀락 (flag와 queue 조작 보호용)
queue_t wait_queue; // 대기 스레드 큐
} mutex_t;
void mutex_lock(mutex_t *m) {
while (test_and_set(&m->guard)) // 내부 스핀락 획득
;
if (m->flag == 0) {
m->flag = 1; // lock 획득 성공
m->guard = 0; // 내부 스핀락 해제
} else {
queue_push(&m->wait_queue, current_thread);
m->guard = 0; // 내부 스핀락 해제
park(); // OS 호출: 현재 스레드를 재움
}
}
void mutex_unlock(mutex_t *m) {
while (test_and_set(&m->guard))
;
if (queue_empty(&m->wait_queue)) {
m->flag = 0; // 대기자 없으면 그냥 해제
} else {
unpark(queue_pop(&m->wait_queue)); // 대기자 깨움
// flag는 1 유지 — 깨어난 스레드가 lock을 이어받음
}
m->guard = 0;
}이 구조가 OSTEP Chapter 28에서 설명하는 park()/unpark() 기반 lock이다. Solaris의 실제 메커니즘을 단순화한 것.
왜 내부 스핀락(guard)이 필요한가?
"sleep하면 되지, 왜 안에 스핀락이 또 있나?"라는 의문이 생길 수 있다. 이유는 뮤텍스 자체의 상태(flag, wait_queue)를 조작하는 코드가 그 자체로 임계 영역이기 때문이다. guard 없이 구현하면 어떤 일이 벌어지는지 보자.
guard 없는 잘못된 구현:
void mutex_lock_broken(mutex_t *m) {
if (m->flag == 0) { // ① flag 확인
m->flag = 1; // ② flag 세팅
} else {
queue_push(&m->wait_queue, current_thread); // ③ 대기 큐에 등록
park(); // ④ sleep
}
}Race 1: flag 확인과 세팅 사이에 끼어들기 (두 스레드가 동시에 lock 획득)
스레드 A 스레드 B
───────── ─────────
① flag == 0 확인 (true)
← 여기서 컨텍스트 스위치 →
① flag == 0 확인 (true)
② flag = 1 (lock 획득)
② flag = 1 (lock 획득)둘 다 flag가 0인 것을 보고 둘 다 lock을 잡는다. 상호 배제 실패.
"그러면 flag를 CAS로 바꾸면 되지 않나?" → flag 자체는 해결되지만, 그다음 문제가 있다.
Race 2: lost wakeup — 깨우기 신호가 허공으로 날아간다
Race 1은 CAS로 해결했다. 하지만 CAS가 실패한 후 "큐에 등록하고 잠드는" 과정에 또 다른 틈이 있다.
void mutex_lock_still_broken(mutex_t *m) {
if (CAS(&m->flag, 0, 1)) { // flag는 atomic하게 처리
return; // lock 획득
}
// CAS 실패 — 누군가 lock을 잡고 있으므로 잠들어야 한다
queue_push(&m->wait_queue, current_thread); // ③ 큐에 등록
// ← 아직 잠들지 않았다! 이 틈이 문제다
park(); // ④ 실제로 잠듦
}핵심은 ③과 ④ 사이의 틈이다. 큐에 이름을 올렸지만 아직 park()는 호출하지 않은 순간이 존재한다.
스레드 A (lock 시도) 스레드 B (unlock)
───────────────── ──────────────
CAS 실패 (flag == 1)
queue_push(A) ← 큐에 등록됨
← 여기서 컨텍스트 스위치 →
queue에서 A를 pop
unpark(A) ← 깨우기 신호 전송!
하지만 A는 아직 안 잠들었다.
신호는 허공으로 사라진다.
flag = 0
park() ← A가 이제야 잠듦
깨워줄 스레드는 이미 지나갔다.
→ A는 영원히 잠든다B가 unpark(A)를 호출한 시점에 A는 아직 park()를 호출하지 않은 상태다. unpark()는 잠들어 있지 않은 스레드에게는 효과가 없으므로 신호가 유실된다. 이후 A가 park()를 호출하면 다시 깨워줄 스레드가 없으므로 영원히 블록된다. 이것이 lost wakeup 문제다.
"CAS 실패 확인 → 큐 등록 → sleep" 이 세 단계 사이에 다른 스레드가 끼어들 수 있기 때문에 발생한다. 그래서 이 세 단계를 하나의 원자적 구간으로 묶어야 하고, 그 역할을 하는 것이 guard 스핀락이다.
guard가 하는 일을 정리하면:
guard가 보호하는 구간 (mutex_lock):
┌─ flag 확인
│ flag 세팅 또는
│ queue에 현재 스레드 추가
└─ guard 해제 (→ 이후 park)
guard가 보호하는 구간 (mutex_unlock):
┌─ queue 확인
│ queue에서 스레드 pop + unpark 또는
│ flag = 0
└─ guard 해제lock과 unlock 양쪽 모두에서 guard를 잡으므로, lock 측의 "flag 확인 + queue 추가"와 unlock 측의 "queue pop + unpark"가 겹칠 수 없다. Race 1과 Race 2가 모두 차단된다.
guard 스핀락은 왜 문제가 안 되나?
guard가 보호하는 구간은 flag 확인 + queue 조작뿐이라 매우 짧다 (수십 나노초). 이 짧은 구간에서만 spinning하니까 CPU 낭비가 사실상 없다. 실제 critical section(사용자 코드)에서는 sleep한다. 즉 뮤텍스의 spinning은 "사용자의 critical section"에 대한 것이 아니라, "뮤텍스 자체의 내부 상태 조작"에 대한 것이다. 이 구간은 고정적으로 짧으므로 스핀락의 단점(CPU 낭비)이 사실상 발생하지 않는다.
Linux의 futex 기반 뮤텍스:
실제 Linux에서 pthread_mutex_lock()은 futex (fast userspace mutex) 위에 구현된다. fast path는 유저스페이스에서 CAS 한 번으로 끝나고, contention이 있을 때만 커널로 진입해서 sleep한다.
pthread_mutex_lock() 동작:
1. CAS(&mutex->state, 0, 1) 시도 ← 유저스페이스, 시스템콜 없음
2. 성공 → lock 획득. 끝.
3. 실패 → futex(FUTEX_WAIT) 시스템콜 → 커널이 스레드를 재움
4. 나중에 unlock에서 futex(FUTEX_WAKE) → 커널이 깨움contention이 없으면 시스템콜이 아예 발생하지 않는다. 이것이 futex가 빠른 이유.
참고: Franke, H., Russell, R., & Kirkwood, M. (2002). "Fuss, Futexes and Furwocks: Fast Userlevel Locking in Linux." Ottawa Linux Symposium.
POSIX pthread 뮤텍스 사용 예시:
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
int shared_counter = 0;
void *worker(void *arg) {
for (int i = 0; i < 100000; i++) {
pthread_mutex_lock(&lock);
shared_counter++; // critical section
pthread_mutex_unlock(&lock);
}
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, worker, NULL);
pthread_create(&t2, NULL, worker, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("counter = %d\n", shared_counter); // 항상 200000
return 0;
}뮤텍스 없이 shared_counter++를 하면 race condition으로 200000보다 작은 값이 나온다. counter++는 load → add → store 3단계이므로 원자적이지 않다.
3. 세마포어 (Semaphore)
뮤텍스의 일반화. 내부에 정수 카운터를 가지고, 이 값이 0 이하면 대기한다.
sem_wait()(= P 연산, down): 카운터 감소. 0 이하면 sleep.sem_post()(= V 연산, up): 카운터 증가. 대기 스레드가 있으면 깨움.
뮤텍스와의 핵심 차이:
| 특성 | 뮤텍스 | 세마포어 |
|---|---|---|
| 내부 값 | 0 또는 1 | 임의의 정수 N |
| 소유권 | lock한 스레드만 unlock 가능 | 아무 스레드나 post 가능 |
| 용도 | 상호 배제 | 상호 배제 + 순서 제어 + 리소스 카운팅 |
소유권 차이가 중요하다. 뮤텍스는 lock한 스레드가 반드시 unlock해야 한다. 세마포어는 스레드 A가 wait하고 스레드 B가 post할 수 있다. 이 특성 때문에 스레드 간 순서 제어(signaling)가 가능하다.
개념적 구현:
typedef struct {
int value;
int guard; // 내부 스핀락
queue_t wait_queue;
} sem_t;
void sem_wait(sem_t *s) {
while (test_and_set(&s->guard))
;
s->value--;
if (s->value < 0) {
queue_push(&s->wait_queue, current_thread);
s->guard = 0;
park(); // sleep
} else {
s->guard = 0;
}
}
void sem_post(sem_t *s) {
while (test_and_set(&s->guard))
;
s->value++;
if (s->value <= 0) {
unpark(queue_pop(&s->wait_queue)); // 대기자 깨움
}
s->guard = 0;
}이 구현은 OSTEP Chapter 31의 Zemaphore를 기반으로 단순화한 것.
용도 1: 이진 세마포어 = 뮤텍스처럼 사용 (초기값 1)
sem_t mutex;
sem_init(&mutex, 0, 1); // 초기값 1
sem_wait(&mutex); // lock
// critical section
sem_post(&mutex); // unlock초기값이 1이므로 한 스레드만 진입 가능. 기능적으로 뮤텍스와 동일하지만, 소유권 검사가 없으므로 다른 스레드가 post할 수도 있다 (이건 보통 버그).
용도 2: 순서 제어 (초기값 0)
스레드 간 실행 순서를 강제할 때 사용. 뮤텍스로는 이걸 직접 할 수 없다.
sem_t order;
sem_init(&order, 0, 0); // 초기값 0
// 스레드 A (먼저 실행되어야 할 작업)
void *thread_a(void *arg) {
printf("A: 작업 완료\n");
sem_post(&order); // "나 끝났어" 시그널
return NULL;
}
// 스레드 B (A가 끝난 후 실행되어야 할 작업)
void *thread_b(void *arg) {
sem_wait(&order); // A가 post할 때까지 여기서 대기
printf("B: A 이후 작업 시작\n");
return NULL;
}B가 먼저 실행되더라도 sem_wait()에서 블록된다. A가 sem_post()를 호출해야 B가 진행된다. 이것이 "외부에서 값 반환이 가능하므로 순서 보장 시 사용"이라고 했던 것의 정확한 의미다.
용도 3: 리소스 카운팅 (초기값 N)
동시에 N개까지 접근을 허용. 대표적 예: 커넥션 풀, bounded buffer.
// bounded buffer (생산자-소비자 문제)
#define BUFFER_SIZE 10
sem_t empty; // 빈 슬롯 수
sem_t full; // 찬 슬롯 수
sem_t mutex; // 버퍼 접근 보호
int buffer[BUFFER_SIZE];
int fill = 0, use = 0;
void init() {
sem_init(&empty, 0, BUFFER_SIZE); // 처음엔 전부 비어있음
sem_init(&full, 0, 0); // 처음엔 아무것도 없음
sem_init(&mutex, 0, 1);
}
void *producer(void *arg) {
for (int i = 0; i < 100; i++) {
sem_wait(&empty); // 빈 슬롯 하나 확보
sem_wait(&mutex); // 버퍼 접근 lock
buffer[fill] = i;
fill = (fill + 1) % BUFFER_SIZE;
sem_post(&mutex); // 버퍼 접근 unlock
sem_post(&full); // 찬 슬롯 하나 증가
}
return NULL;
}
void *consumer(void *arg) {
for (int i = 0; i < 100; i++) {
sem_wait(&full); // 찬 슬롯 하나 확보
sem_wait(&mutex);
int val = buffer[use];
use = (use + 1) % BUFFER_SIZE;
sem_post(&mutex);
sem_post(&empty); // 빈 슬롯 하나 증가
printf("consumed: %d\n", val);
}
return NULL;
}empty와 full 세마포어가 생산자와 소비자 간 흐름 제어를 담당한다. 버퍼가 꽉 차면 생산자가 블록되고, 비면 소비자가 블록된다.
이 패턴은 Dijkstra(1965)가 세마포어를 처음 제안할 때의 핵심 예제이며, OSTEP Chapter 31에서도 동일하게 다룬다.
정리
스핀락:
- 구현: atomic instruction + busy-wait loop
- 대기 방식: CPU를 소모하며 반복 확인 (spinning)
- 사용처: 커널 내부, 짧은 critical section, sleep 불가능한 컨텍스트
뮤텍스:
- 구현: 내부 스핀락 + OS sleep/wakeup (futex 등)
- 대기 방식: lock 못 잡으면 sleep → unlock 시 wakeup
- 소유권: lock한 스레드만 unlock
- 사용처: 유저스페이스 상호 배제의 기본
세마포어:
- 구현: 정수 카운터 + 내부 스핀락 + OS sleep/wakeup
- 대기 방식: 카운터 ≤ 0이면 sleep
- 소유권: 없음 (아무나 post 가능)
- 사용처: 상호 배제, 순서 제어, 리소스 카운팅참고 문헌:
- Arpaci-Dusseau, R. & Arpaci-Dusseau, A. Operating Systems: Three Easy Pieces (OSTEP). Chapters 28–31.
- Herlihy, M. (1991). "Wait-free synchronization." ACM TOPLAS, 13(1).
- Dijkstra, E. W. (1965). "Cooperating Sequential Processes." Technical Report EWD-123.
- Love, R. (2010). Linux Kernel Development, 3rd ed. Addison-Wesley.